zmalloc.c
tcmalloc
jemalloc
1 | /* 申请新的_n大小的内存,用新的gcc原子方法(__atomic_add_fetch)代替之前的 代替自定义的线程安全方法和不安全方法*/ |
详情可以参考GCC官方文档链接
- 分配内存大小为size+PREFIX_SIZE的大小,zmalloc实际分配比需要多一些的内存,这一部分用于存储size信息。
- zmalloc_oom_handler用来处理内存申请异常
- (_n&(sizeof(long)-1)) _n += sizeof(long)-(_n&(sizeof(long)-1)); = if(_n&7) _n += 8 - (_n&7); 32位4字节对齐,64位下8字节对齐
数据结构:objcet
1 | typedef struct redisObject { |
1 | type字段表示数据类型,有以下几种定义: |
1 | //encoding则对应了 Redis 中的10种编码方式 |
| 数据类型 | 一般情况 | 少量情况 | 特殊情况 |
|---|---|---|---|
| STRING | RAW | EMBSTR | INT |
| LIST | LINKEDLIST | ZIPLIST | |
| HASH | HT | ZIPLIST |
refcount 引用计数的方式管理内存,自动化的管理除了引用技术,就是垃圾回收,相关可以参考云风写的引用计数与垃圾收集之比较
1 | //objcet.c基本上就是提供了一堆对象操作,初始化等相关的api接口 |
Redis中采用两种算法进行内存达到上限时内存回收,引用计数算法以及LRU/LFU算法
- 引用计数 refcount
- lru (Least Recently Used)//最长时间未被使用
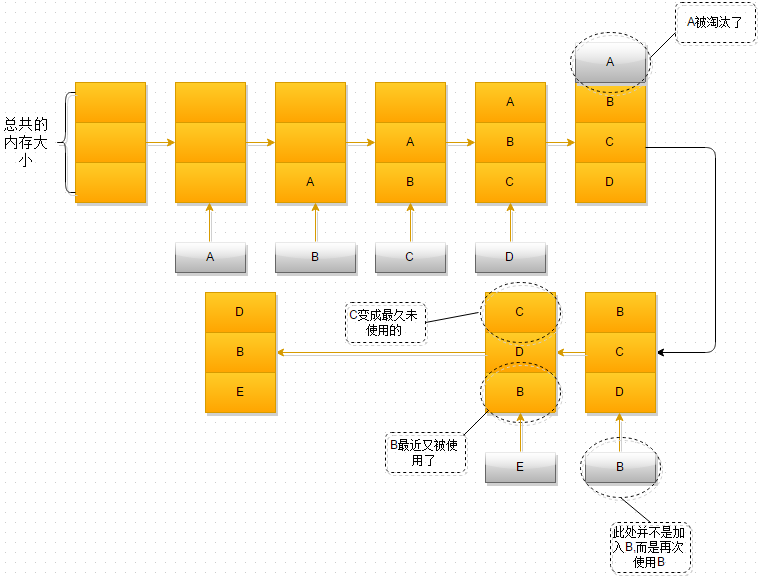

1 |
|
3.LFU(Least Frequently Used) 最不常用页面置换算法,基于LFU的热点key发现机制 4.0
counter:基于概率的对数计数器
1 | uint8_t LFULogIncr(uint8_t counter) { |

counter增长函数LFULogIncr中我们可以看到,随着key的访问量增长,counter最终都会收敛为255,一百万
动态配置
1 | lfu-log-factor 10 概率因子 |
1 | //更新对象的访问时间和计数器值,减少,每分钟 |
redis内存达到上限后的释放内存原则
- 释放内存的标准是释放之后使用内存的大小小于maxmemory的大小
- 每次释放的数量,redis.conf配置
- 超过限制后redis策略
1 | redis.conf配置 |
如何筛选释放的key
1 |
|
根据配置策略的LRU、LFU以及volatile-ttl策略转换成的idle值将待删除的键相关的信息按照idle值从小到大的顺序从前向后存储在evctionPoolLRU中
1 | void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) { |
统计内存是否超过server.maxmemory,去掉AOF,slaves缓冲区内存占用
1 | /* Remove the size of slaves output buffers and AOF buffer from the |
内存管理策略的入口函数—freeMemoryIfNeeded()
1 | int freeMemoryIfNeeded(void) { |
后续优化方向
- 淘汰算法的优化,更有效的需要淘汰的key
- 算法对性能,内存的影响
过期key删除策略
惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,那就返回该键;
1 | int expireIfNeeded(redisDb *db, robj *key) { |
lazyfree机制 删除大数据的键值,导致redis阻塞,4.0引入的,将删除键或数据库的操作放在后台线程里执行, 从而尽可能地避免服务器阻塞。
redis 思考
- redis4.0引入的命令 unlink(unlinkCommand)
- FLUSHALL/FLUSHDB ASYNC 线上禁用
- Lazy 应该全开
定期删除:每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键。至于删除多少过期键,以及要检查多少个数据库,则由算法决定。 如何确定频率时长
- databasesCron -> activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);分多次
遍历各个数据库,从expires字典中随机检查一部分过期键的过期时间,删除其中的过期键
1 |
|
- 事件处理函数aeMain beforeSleep activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST);
- 访问key 判断lookupKeyRead,过期删除
持久化rdb/aof
rdbrdb程序就是将内存中的数据库的数据结构以rdb文件形式保存到磁盘;在redis重启时,rdb程序就通过载入rdb文件来还原重启前的数据库状态
- RDB文件创建两个命令可以生成RDB文件:SAVE和BGSAVE。

SAVE命令会阻塞redis的服务器进程,直到RDB文件创建完毕为止。在阻塞过程中,server不能处理任何请求 saveCommand->rdbSave->rdbSaveRio->rdbSaveKeyValuePair
REDIS // RDB协议约束的固定字符串
0006 // redis的版本
FE 00 // 表示当前接下来的key都是db=0中的key;
FC 1506327609 // 表示key失效时间点为1506327609
0 // 表示key的属性是string类型
username // key
afei // value
FF // 表示遍历完成
y73e9iq1 // checksum , CRC64

BGSAVE则会fork出一个子进程,然后子进程负责RDB文件的创建,父进程继续处理请求。
fork()系统调用我们可以创建一个和当前进程一样的新进程,继承了父进程的整个地址空间,其中包括了进程上下文,堆栈地址,内存信息进程控制块
bgsaveCommand->rdbSaveBackground-> rdbSave
fork危害,多进程的多线程程序
自动执行bgsave,配置redis.conf
save “”
save 900 1
save 300 10
save 60 10000
只要这三个条件中的任意一条符合,那么服务器就会执行BGSAVE。配置保存在 redisServer saveparam中,serverCron中判断执行
rdb加载,loadDataFromDisk -> rdbLoad(),阻塞
aof记录服务器所处理的所有的除查询意外的操作,以文本的方式记录
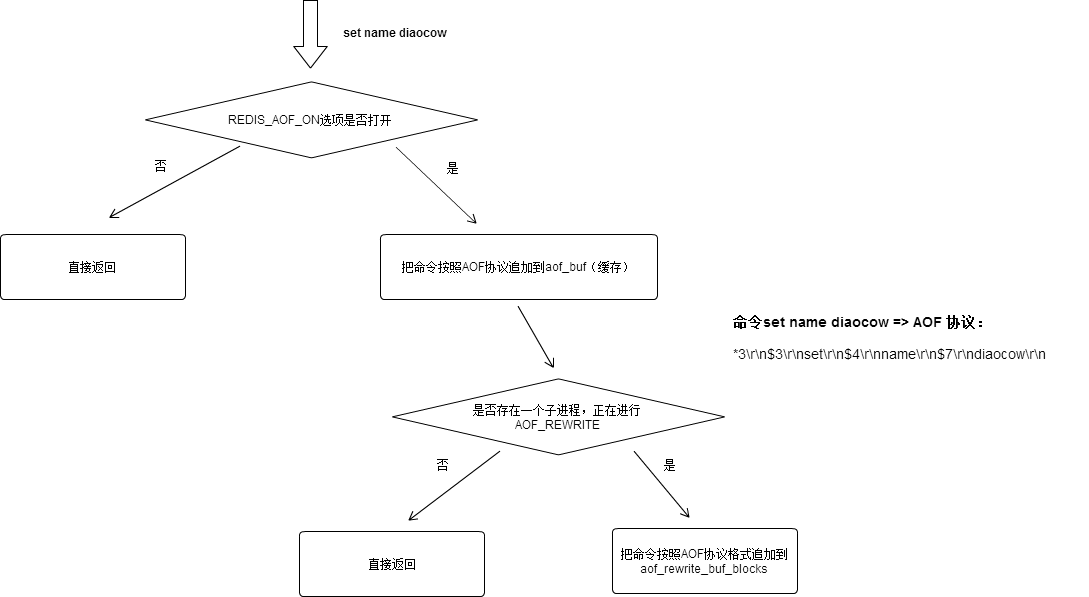
原理是:处理文件事件执行写命令,使得命令被追加到aof_buf中,,然后在处理时间事件执行serverCron函数会调用flushAppendOnlyFile函数进行文件的写入和同步。
appendonly yes
appendfilename “appendonly.aof”
appendfsync everysec
always:将aof_buf中的所有内容写入并同步到aof文件。
everysec:将aof_buf中的所有内容写入到aof文件,如果上次同步的时间距离现在超过1s,那么对aof文件进行同步,同步操作由一个线程专门负责执行
no:将aof_buf中的所有内容写入到aof文件,但不对aof文件同步,同步有操作系统执行。aof流程主要函数:
//函数1:将command写入aof_buff propagate-> feedAppendOnlyFile,数据修改更新到AOF缓存中
//函数2:启动子进程,后台用于整理aof的数据 serverCron-> rewriteAppendOnlyFileBackground
//函数3:刷一遍server.db[16],依次将对象写入磁盘临时文件tmpfile,rewriteAppendOnlyFile ->rewriteAppendOnlyFileRio
//函数4:将aof_buff内容持久化flushAppendOnlyFile
//函数5:将backgroundRewriteDoneHandler 更新子进程同步期间产生的修改aof_rewrite 解决AOF文件体积膨胀的问题
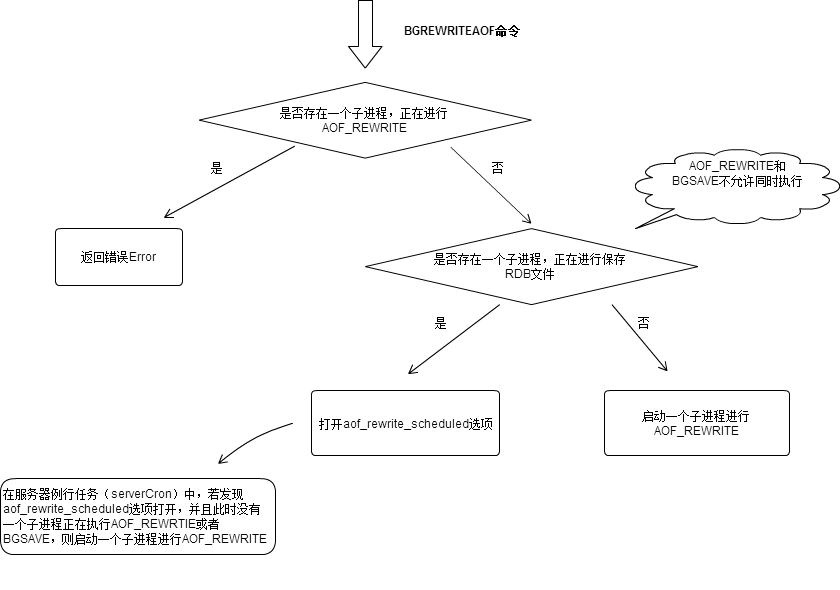
触发条件- 被动: 当AOF文件尺寸超过conf:auto-aof-rewrite-min-size 64mb & 达到一定增长比,
指当前aof文件比上次重写的增长比例大小 auto-aof-rewrite-percentage 100; - 主动: 调用BGREWRITEAOF命令;
对应bgrewriteaofCommand逻辑
- 被动: 当AOF文件尺寸超过conf:auto-aof-rewrite-min-size 64mb & 达到一定增长比,
混合持久化 conf aof-use-rdb-preamble no, aof rewrite 的时候就直接把 rdb 的内容写到 aof 文件开头
1 | +------------------------+ |
rdb优缺点:二进制文件,速度快,存在数据丢失,性能消耗低
aof优缺点:数据丢失小,性能消耗大,4.0管道优化相对好些
混合持久化:加载速度快,避免丢失数据
事故案例:陌陌争霸
32 个数据仓库部署到 4 台物理机上即可,每台机器上启动 8 个 Redis 进程。使用 64G 内存的机器,后来增加到了 96G 内存。实测每个 Redis 服务会占到 4~5 G 内存,四台配置相同的从主机进行主从备份。
事故1:有一台数据服务主机无法被游戏服务器访问到,影响了部分用户登陆,运维维护时发现,一台从机的内存耗尽,导致了从机的数据库服务重启。在从机重新对主机连接,8 个 Redis 同时发送 SYNC 的冲击下,把主机击毁了。
问题1:从主机为什么出现内存不足
原因:redis 服务同时做 BGSAVE,概率性 ,而导致 fork 多个进程需要消耗太多内存
问题2:重新进行 SYNC 操作会导致主机过载
原因:重启后,8 个 slave redis 同时开启同步,等于瞬间在主机上 fork 出 8 个 redis 进程
解决方案:取消主从,脚本控制bgsave
事故2:内存内存不足
原因:定期备份redis数据库文件,拷贝数据库文件时,系统使用大量的内存做为cache,释放不及时,脚本控制bgsave,内存不住,使用交换分区,脚本保证30分钟内必须执行一次bgsave
思考:1.备份方案的选择。2.使用leveldb做redis的持久化存储 3.redis内存上限设置一半
hyperloglog.c
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。HyperLogLog只会根据输入元素来计算基数,而不会储存输入元素本身
##看到第一句话就知道这个已经完全没有了解的必要了,逆天的算法,用于比如ip访问数的基数统计。
+ 动态字符串 sds.h和sds.c
+ 双端链表 adlist.c和adlist.h
+ 字典 dict.h和dict.c
+ 跳跃表 server.h文件里面关于zskiplist结构和zskiplistNode结构,以及t_zset.c中所有zsl开头的函数,比如 zslCreate、zslInsert、zslDeleteNode等等。
+intset.c和intset.h
- intset 是一种有序的整型集合,共有
INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT64编码类型。 - intset
length属性记了录集合的大小。 - intset 内部采用
二分查找算法定位元素。 - intset 只会升级,不会降级。当将一个高位元素添加到低编码集合时,此时,需要对集合进行升级。
这几个百度一下基本上能理解实现原理,唯一的用途估计也就是面试的时候拿来测试为难或者测试一下面试者的底线。
ziplist.c和ziplist.h
- 实在是不想看实现了,估计也看不懂,看名字就知道是一种极节内存内存的链表,redis是内存性数据库,肯定还是要能省则省,代码肯定是有的,肯定是性能稍微差一点,但是应该差的不多,大神撸出来的东西是不用有任何怀疑的。